


Наверняка не раз возникала такая ситуация, что вы нашли хороший дроп с индексом, но вот восстановить его не от куда. В веб-архиве отсутствуют стили или страницы, другие способы тоже не помогают. Хороший сайт пропадает, который можно было бы переделать/подклеить/монетизировать/еще как-то использовать. Но не все потеряно, есть еще один, не самый очевидный способ восстановления дропов.
Наверняка многие из вас знают, что браузер получает содержимое любого сайта по IP адресу, предварительно запросив в службе DNS на каком сервере в интернете он располагается, добавляя специальную директиву HOST в заголовок http запроса. На самом деле так работает не только браузер, а много что еще.
Таким образом, содержимое любого сайта можно получить отправив простой запрос на IP адрес сервера с заголовком host: domainname.ru, можете сами попробовать в утилите cURL.
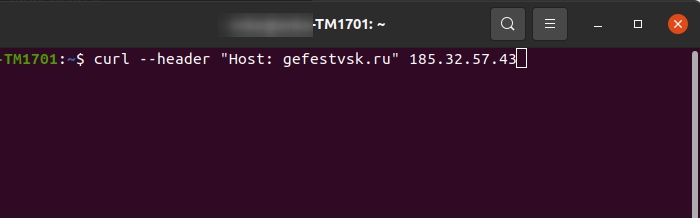
Наверное у вас уже возник вопрос, зачем все это надо, если можно получить страницы по адресу домена. Дело все в том, что таким способом мы получаем данные напрямую с сервера, минуя все службы DNS.
Да, конечно, можно просто найти старые ns сервера в истории Whois, но способ c IP работает даже до регистрации домена на вас и дает чуть больше шансов успешно выкачать содержимое сайта. Потому что некоторые хостинги после окончания оплаты приостанавливают только DNS для домена, хотя сами файлы продолжают храниться на серверах. Тоже самое относиться и к выделенным серверам, на которых размещалось несколько сайтов. Владелец мог просто удалить сайт из DNS панели, но настройки сервера остались без изменений. Нужно только знать IP адрес сервера, на котором хранятся файлы.
Где взять старый IP-адрес
В этом поможет наш новый инструмент История IP-адресов сайта. Он абсолютно бесплатный и работает без ограничений.
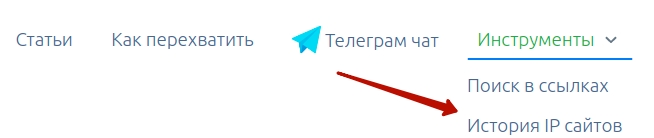
Пользоваться предельно просто, достаточно вбить адрес перехваченного домена, содержимое которого вы хотите восстановить.
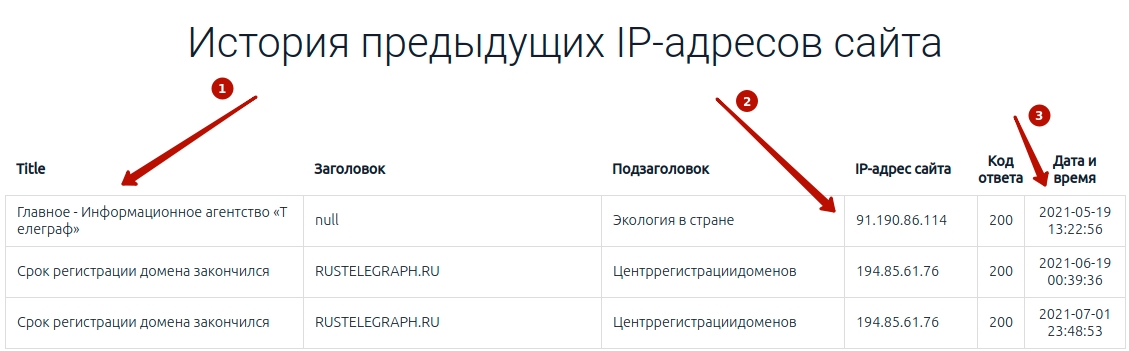
Далее все просто, необходимо понять по тайтлу и заголовкам, когда сайт еще работал, этот IP нам и нужен.
Что делать с полученным IP
UPD: Найден способ еще проще и лучше. Можно использовать для проверки наличия файлов на хостинге еще до дропа домена. Это позволяет совершенно бесплатно сделать сервис archivarix.com, но, все же с регистрацией.
Для этого просто укажите домен и ip на данной странице — https://archivarix.com/ru/restore/ И если страницы присутствуют, то вы это поймете, появится скриншот главной страницы (а не ошибка 404 или заглушка хостинга).
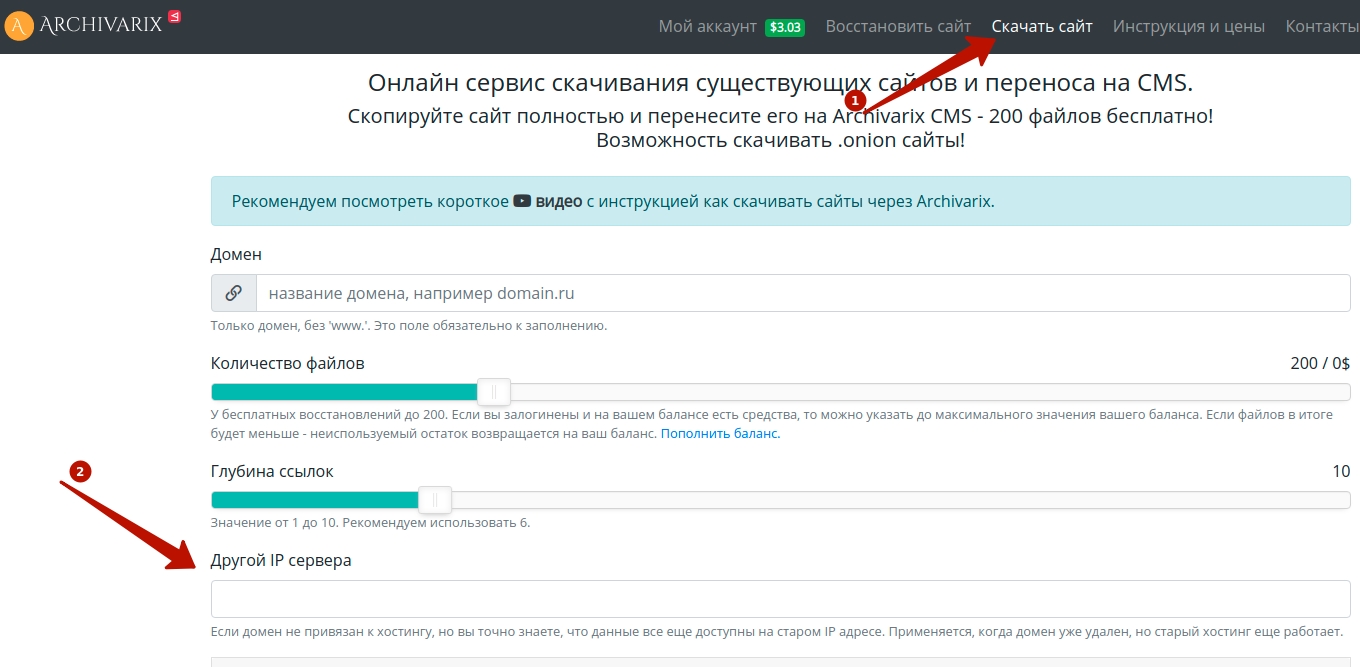
Далее смотрите по обстоятельствам, если сайт маленький, до 200 файлов, то архиварикс вам бесплатно его скачает и подготовит архив. Бонусом будет довольно неплохая CMS. Если же сайт большой, то переходим к способам ниже — они бесплатные, либо можете заплатить пару баксов архивариксу, ребята этого заслуживают, тут уже на ваше усмотрение.
Способ через DNS панель
Для этого домен должен быть уже ваш, чтобы можно было указать свои NS записи. Для этого просто добавляйте домен к любому хостингу, который позволяет редактировать ресурсные записи типа А. Подойдет почти любой хостинг, я покажу на примере Fornex.
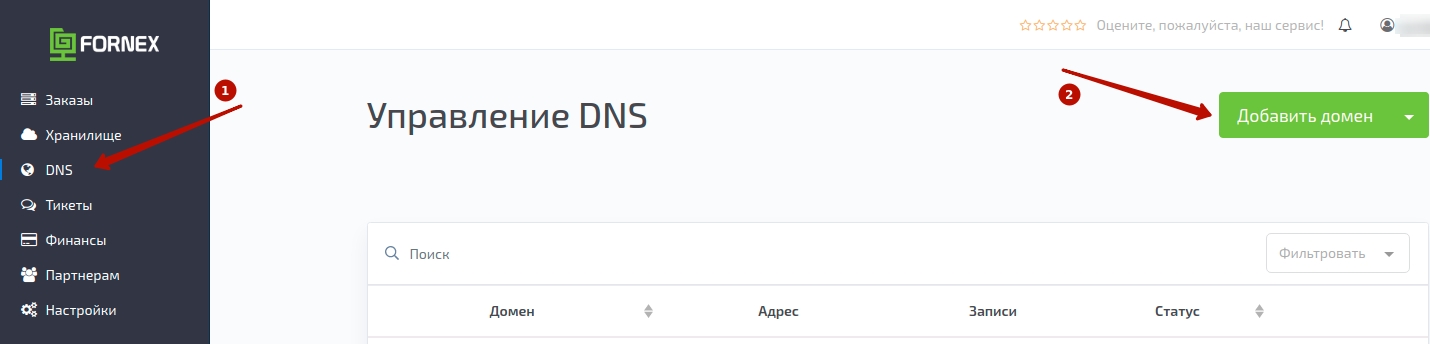
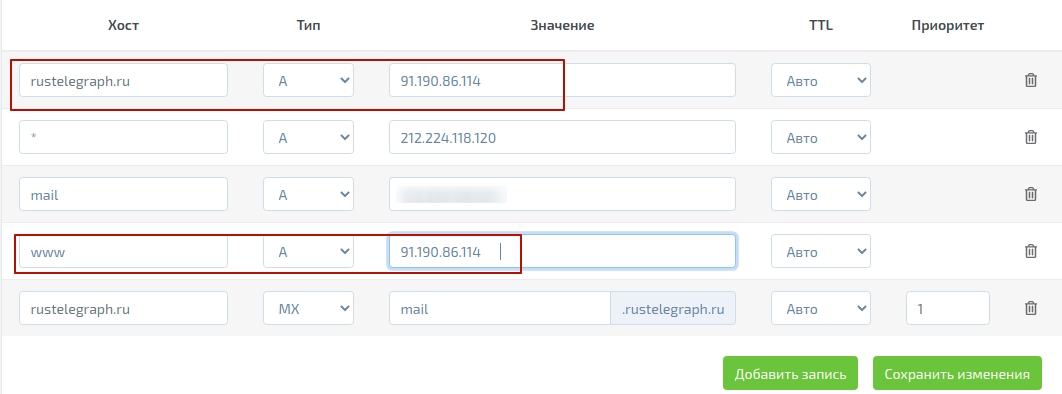
Сначала добавляем домен в панель управления хостинга, затем прописываем NS сервера этого хостинга для домена в панели регистратора, затем нужно будет изменить IP для основного домена и для www в записях типа A на полученный.
Также для этих целей можно использовать Clouflare или Clouddnd, но на время скачивания сайта нужно будет установить режим обслуживания в их панели, чтобы они не блокировали запросы и не показывали капчу.
Далее дождитесь обновления NS серверов у домена, после чего сайт должен работать, если он не еще не удален с сервера, можете скачивать его с помощью wget по этой инструкции, если у вас Windows, либо с помощью данной команды в терминале, если Linux (кавычки нужно заменить на обычные двойные):
wget -r -l10 -k -p -nc —header=»Accept: text/html» —user-agent=»Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36″ —no-check-certificate —random-wait —referer=https://google.com/ vash-drop.ru
Еще один способ выкачать сайт со старого ip:
Данный способ не требует, чтобы домен принадлежал вам, как и в случае с Архивариксом, можно проверить любой, но ограничений на 200 файлов уже нет. Если сайт заработал после того, как прописали домен и ip в файле hosts (актуально и для Windows и для LInux), то выкачиваем с помощью wget, как указано выше, либо как показано в самом видео.
На этом все, если есть вопросы, задавайте их в комментариях.





